Mapeadores relacionales de objetos (ORM) – Lenguaje Python
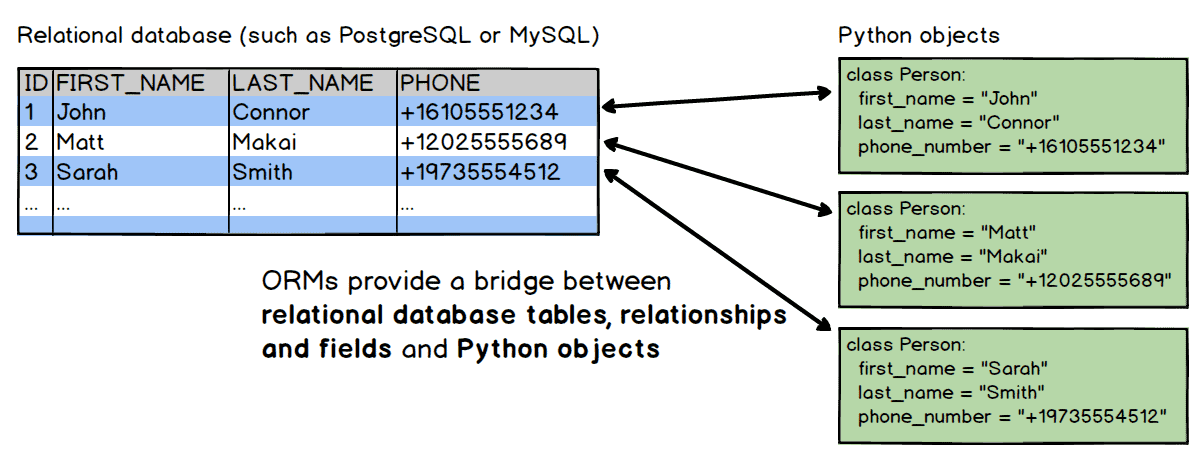
Un mapeador relacional de objetos (ORM) es una biblioteca de código que automatiza la transferencia de datos almacenados en tablas de bases de datos relacionales a objetos que se usan más comúnmente en el código de la aplicación.
Contrata a un experto en Python para iniciar tu proyecto hoy mismo:
¿Por qué son útiles los ORM?
Los ORM proporcionan una abstracción de alto nivel sobre una base de datos relacional que permite a un desarrollador escribir código Python en lugar de SQL para crear, leer, actualizar y eliminar datos y esquemas en su base de datos. Los desarrolladores pueden utilizar el lenguaje de programación con el que se sientan cómodos para trabajar con una base de datos en lugar de escribir declaraciones SQL o procedimientos almacenados.
Por ejemplo, sin un ORM, un desarrollador escribiría la siguiente declaración SQL para recuperar cada fila en la tabla USERS donde el
zip_code columna es 94107:
SELECT * FROM USERS WHERE zip_code=94107;
La consulta ORM de Django equivalente se vería en cambio como el siguiente código de Python:
# obtain everyone in the 94107 zip code and assign to users variable
users = Users.objects.filter(zip_code=94107)
La capacidad de escribir código Python en lugar de SQL puede acelerar el desarrollo de aplicaciones web, especialmente al comienzo de un proyecto. El potencial aumento de la velocidad de desarrollo proviene de no tener que cambiar del código Python a escribir declaraciones SQL de paradigma declarativo. Si bien es posible que a algunos desarrolladores de software no les importe cambiar entre lenguajes, normalmente es más fácil eliminar un prototipo o iniciar una aplicación web con un solo lenguaje de programación.
Los ORM también permiten teóricamente cambiar una aplicación entre varias bases de datos relacionales. Por ejemplo, un desarrollador podría usar SQLite para el desarrollo local y MySQL en producción. Una aplicación de producción podría cambiarse de MySQL a PostgreSQL con modificaciones mínimas de código.
Sin embargo, en la práctica, es mejor utilizar la misma base de datos para el desarrollo local que se utiliza en producción. De lo contrario, podrían producirse errores inesperados en la producción que no se vieron en un entorno de desarrollo local. Además, es raro que un proyecto cambie de una base de datos en producción a otra a menos que haya una razón urgente.
¿Tengo que usar un ORM para mi aplicación web?
Las bibliotecas de Python ORM no son necesarias para acceder a las bases de datos relacionales. De hecho, el acceso de bajo nivel lo proporciona normalmente otra biblioteca llamada conector de base de datos, como psycopg (para PostgreSQL) o MySQL-python (para MySQL). Eche un vistazo a la tabla a continuación, que muestra cómo los ORM pueden funcionar con diferentes marcos y conectores web y bases de datos relacionales.
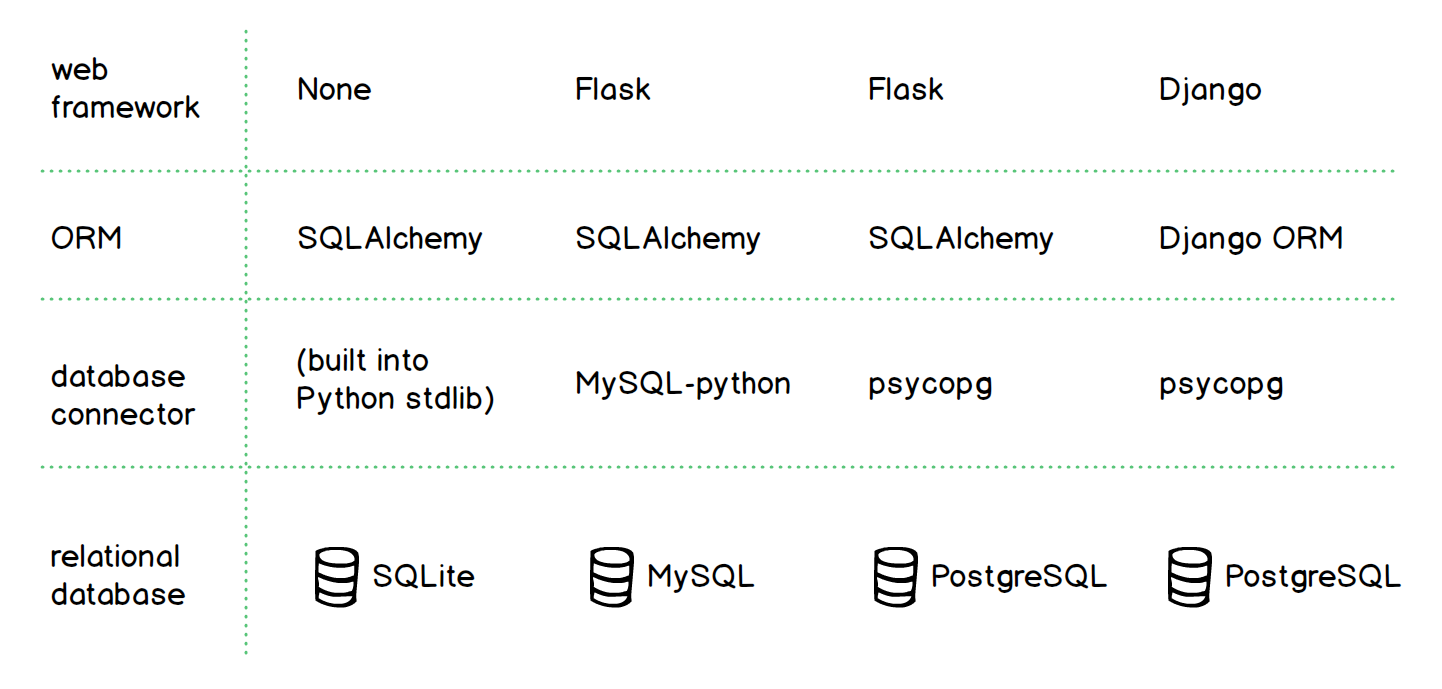
La tabla anterior muestra, por ejemplo, que SQLAlchemy puede funcionar con diferentes marcos web y conectores de bases de datos. Los desarrolladores también pueden usar ORM sin un marco web, como cuando crean una herramienta de análisis de datos o un script por lotes sin una interfaz de usuario.
¿Cuáles son las desventajas de usar un ORM?
Existen numerosas desventajas de los ORM, que incluyen
- Desajuste de impedancia
- Potencial de rendimiento reducido
- Cambiar la complejidad de la base de datos al código de la aplicación
Desajuste de impedancia
La frase «desajuste de impedancia» se usa comúnmente junto con los ORM. El desajuste de impedancia es un término general para las dificultades que ocurren al mover datos entre tablas relacionales y objetos de aplicación. La esencia es que la forma en que un desarrollador usa los objetos es diferente de cómo se almacenan y se unen los datos en tablas relacionales.
Este artículo sobre el desajuste de impedancia de ORM hace un trabajo sólido al explicar cuál es el concepto a un alto nivel y proporciona diagramas para visualizar por qué ocurre el problema.
Potencial de rendimiento reducido
Una de las preocupaciones asociadas con cualquier marco o abstracción de nivel superior es la posibilidad de que se reduzca el rendimiento. Con los ORM, el impacto en el rendimiento proviene de la traducción del código de la aplicación en una declaración SQL correspondiente que puede no ajustarse correctamente.
Los ORM también suelen ser fáciles de probar pero difíciles de dominar. Por ejemplo, un principiante que usa Django puede que no conozca la
select_related() función y cómo puede mejorar el rendimiento de la relación de clave externa de algunas consultas. Hay docenas de consejos y trucos de rendimiento para cada ORM. Es posible que invertir tiempo en aprender esas peculiaridades se gaste mejor simplemente aprendiendo SQL y cómo escribir procedimientos almacenados.
En esta sección hay muchos gestos con la mano «puede o no» y «potencial para». En proyectos grandes, los ORM son lo suficientemente buenos para aproximadamente el 80-90% de los casos de uso, pero en el 10-20% de las interacciones de la base de datos de un proyecto puede haber importantes mejoras de rendimiento al hacer que un administrador de base de datos experimentado escriba declaraciones SQL ajustadas para reemplazar el código SQL generado por el ORM .
Cambiar la complejidad de la base de datos al código de la aplicación
El código para trabajar con los datos de una aplicación tiene que vivir en algún lugar. Antes de que los ORM fueran comunes, los procedimientos almacenados de la base de datos se usaban para encapsular la lógica de la base de datos. Con un ORM, el código de manipulación de datos vive dentro de la base de código Python de la aplicación. La adición de lógica de manejo de datos en la base de código generalmente no es un problema con un diseño de aplicación sólido, pero aumenta la cantidad total de código Python en lugar de dividir el código entre la aplicación y los procedimientos almacenados de la base de datos.
Implementaciones de Python ORM
Existen numerosas implementaciones de ORM escritas en Python, incluidas
- SQLAlchemy
- Peewee
- El ORM de Django
- PonyORM
- SQLObject
- Tortuga ORM
(código fuente)
Hay otros ORM, como Canonical Storm, pero la mayoría de ellos no parece estar actualmente en desarrollo activo. Obtenga más información sobre los principales ORM activos a continuación.
ORM de Django
El marco web de Django viene con su propio módulo de mapeo relacional de objetos incorporado, generalmente denominado «el ORM de Django» o «ORM de Django».
ORM de Django funciona bien para operaciones de bases de datos simples y de complejidad media. Sin embargo, a menudo hay quejas de que el ORM hace que las consultas complejas sean mucho más complicadas que escribir SQL directo o usar SQLAlchemy.
Es técnicamente posible pasar a SQL pero vincula las consultas a una implementación de base de datos específica. El ORM está estrechamente relacionado con Django, por lo que reemplazar el ORM predeterminado con SQLAlchemy es actualmente una solución alternativa. Sin embargo, tenga en cuenta que es posible que los backends de ORM intercambiables sean posibles en el futuro, ya que ahora es posible cambiar el motor de plantillas para representar la salida en Django.
Dado que la mayoría de los proyectos de Django están vinculados al ORM predeterminado, es mejor leer sobre casos de uso avanzados y herramientas para hacer su mejor trabajo dentro del marco existente.
SQLAlchemy ORM
SQLAlchemy es un ORM de Python bien considerado porque obtiene el nivel de abstracción «justo» y parece hacer que las consultas de bases de datos complejas sean más fáciles de escribir que el ORM de Django en la mayoría de los casos. Hay una página completa sobre SQLAlchemy que debe leer si desea obtener más información sobre el uso de la biblioteca.
ORM de pipí
Peewee es una implementación de Python ORM que está escrita para ser «más simple, más pequeño y más pirateable«que SQLAlchemy. Lea la página completa de Peewee para obtener más información sobre la implementación de Python ORM.
Poni
Pony ORM es otro ORM de Python disponible como código abierto, bajo la licencia Apache 2.0.
SQLObject ORM
SQLObject es un ORM que ha estado en desarrollo activo de código abierto durante más de 14 años, desde antes de 2003.
Migraciones de esquemas
Las migraciones de esquemas, por ejemplo, cuando necesita agregar una nueva columna a una tabla existente en su base de datos, no son técnicamente parte de los ORM. Sin embargo, dado que los ORM generalmente conducen a un enfoque de no intervención en la base de datos (a riesgo de los desarrolladores en muchos casos), las bibliotecas para realizar migraciones de esquemas a menudo van de la mano con el uso de Python ORM en proyectos de aplicaciones web.
Las migraciones de esquemas de bases de datos son un tema complejo y merecen su propia página. Por ahora, agruparemos los recursos de migración de esquemas en los enlaces ORM a continuación.
Recursos generales de ORM
- Esta descripción detallada de los ORM
es una descripción genérica de cómo funcionan los ORM y cómo utilizarlos. - Esta ejemplo de proyecto de GitHub
implementa la misma aplicación Flask con varios ORM diferentes: SQLAlchemy, Peewee, MongoEngine, stdnet y PonyORM. - Martin Fowler aborda el Odio ORM
en un ensayo sobre cómo los ORM a menudo se usan incorrectamente pero que brindan beneficios a los desarrolladores. - El auge y la caída del mapeo relacional de objetos
es una charla sobre la historia de los ORM que no rehuye ninguna controversia. En general, encontré que la crítica de las ideas conceptuales valió la pena el tiempo que tomó leer las diapositivas de la presentación y el texto complementario. - Si está confundido acerca de la diferencia entre un conector, como MySQL-python y un ORM como SQLAlchemy, lea esto Respuesta de StackOverflow en el tema.
- Lo que me han enseñado los ORM: solo aprende SQL
es otro ángulo en el debate sobre ORM versus SQL incorporado / procedimientos almacenados. La conclusión del autor es que mientras se trabaja con ORM como SQLAlchemy e Hibernate (un ORM basado en Java) puede ahorrar tiempo desde el principio, hay problemas a medida que un proyecto evoluciona, como objetos parciales y redundancias de esquemas. Creo que el autor hace algunos puntos válidos de que algunos ORM pueden ser una base inestable para aplicaciones respaldadas por bases de datos extremadamente complicadas. Sin embargo, no estoy de acuerdo con la conclusión primordial de evitar los ORM en favor de los procedimientos almacenados. Los procedimientos almacenados tienen sus propios problemas y no hay soluciones perfectas, pero personalmente prefiero usar un ORM al comienzo de casi todos los proyectos, incluso si más adelante debe reemplazarse con consultas SQL directas. - El Vietnam de la informática
proporciona la perspectiva de Ted Neward, el creador de la frase «El mapeo de objetos / relacional es el Vietnam de la informática» de la que habló por primera vez en 2004. La esencia del argumento contra los ORM se captura en la cita de Ted de que un ORM «representa un un atolladero que comienza bien, se vuelve más complicado a medida que pasa el tiempo, y en poco tiempo atrapa a sus usuarios en un compromiso que no tiene un punto de demarcación claro, condiciones claras de victoria y una estrategia de salida clara «. Hay publicaciones de seguimiento en Horror de codificación y otro de Ted titulado pensamientos sobre el comentario de Vietnam. - Cambiando las tornas: cómo llevarse bien con su mapeador relacional de objetos acuña la divertida pero perspicaz frase «denegación de base de datos» para describir cómo algunos ORM proporcionan un modelo de uso que puede causar más problemas de los que resuelven en consultas SQL directas. Luego, la publicación entra en muchos más detalles sobre los problemas que pueden surgir y cómo mitigarlos o evitarlos.
Recursos de SQLAlchemy y Peewee
Puede encontrar una lista completa de los recursos de SQLAlchemy y Peewee ORM en sus respectivas páginas.
Enlaces de Django ORM
Se puede encontrar una lista curada de recursos en la página dedicada de recursos de Django ORM.
Recursos de Pony ORM
Todos los recursos de Pony ORM se enumeran en la página dedicada de Pony ORM.
Recursos de SQLObject
SQLObject ha existido durante mucho tiempo como un proyecto de código abierto, pero desafortunadamente no hay tantos tutoriales para él. Las siguientes charlas y publicaciones te ayudarán a comenzar. Si se interesa por el proyecto y escribe recursos adicionales, presente una emitir boleto para que podamos agregarlos a esta lista.
¿Qué le gustaría aprender sobre la creación de aplicaciones web Python?
¿Necesitas ayuda para revisar el código de tu proyecto?
También te puede interesar:




Esta entrada tiene 0 comentarios